Motivation
The Gap in Current Deep Research Systems
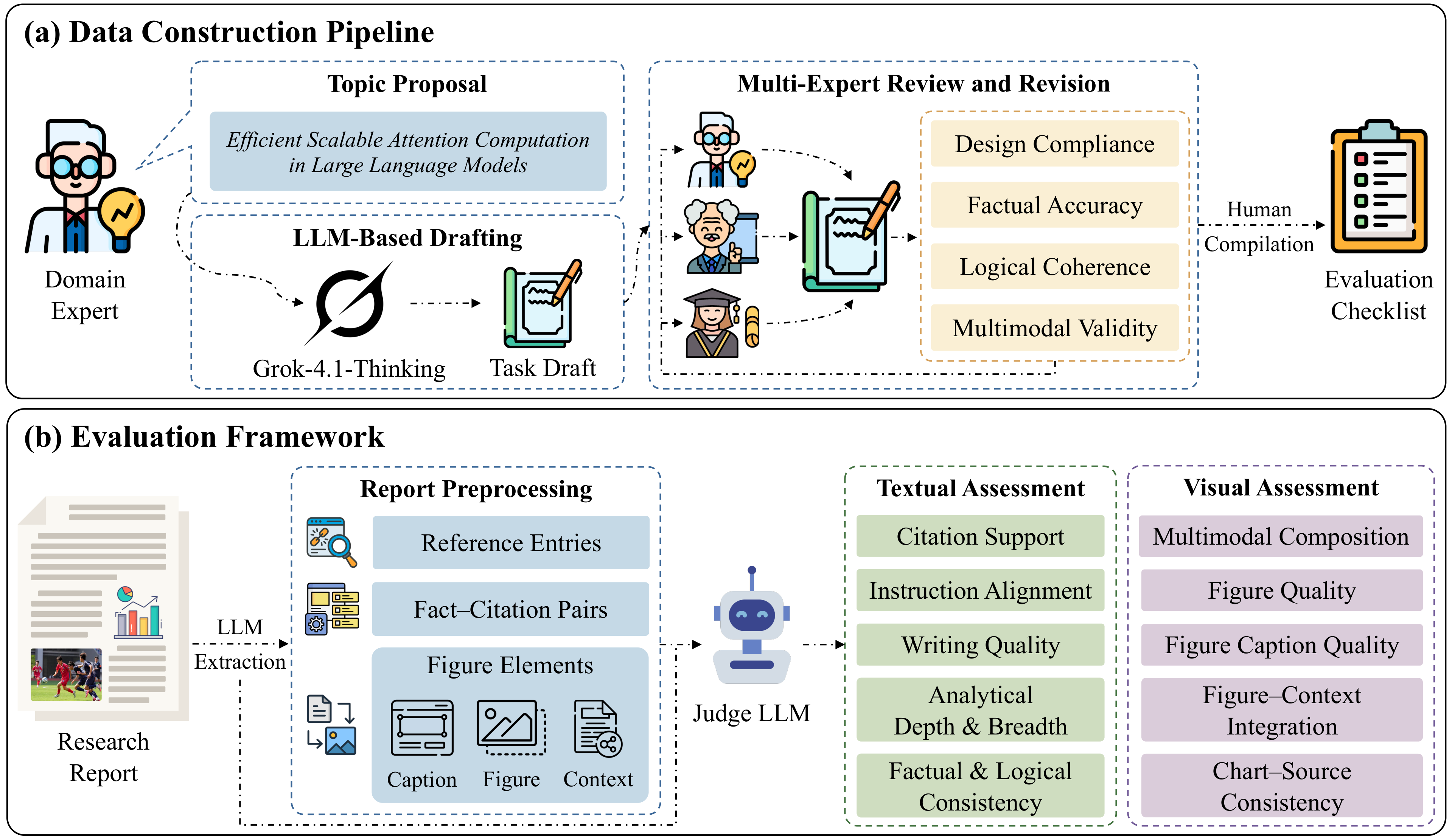
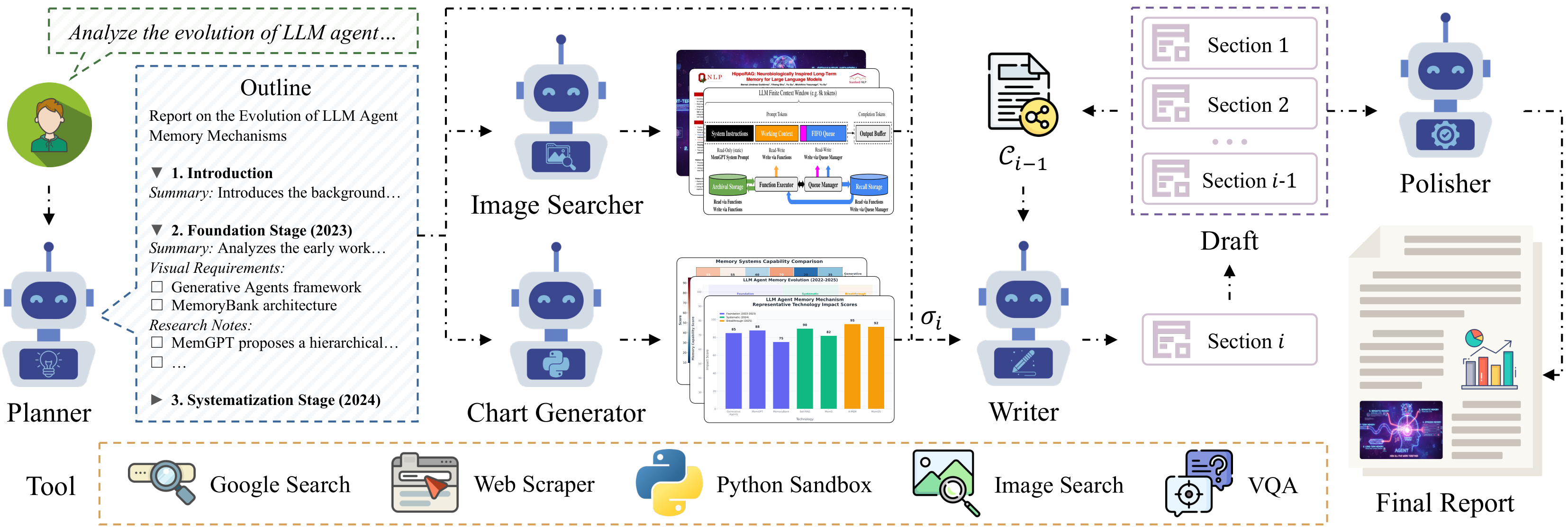
Existing deep research paradigms remain predominantly text-centric. Most benchmarks and agent frameworks evaluate success based on textual coherence, depth, and citation support, while overlooking a critical characteristic of real-world professional reports: the integration of visual evidence.
Visual elements treated as decorative supplements
Limited evaluation of visual fidelity and provenance
Mismatch between benchmarks and real-world demands

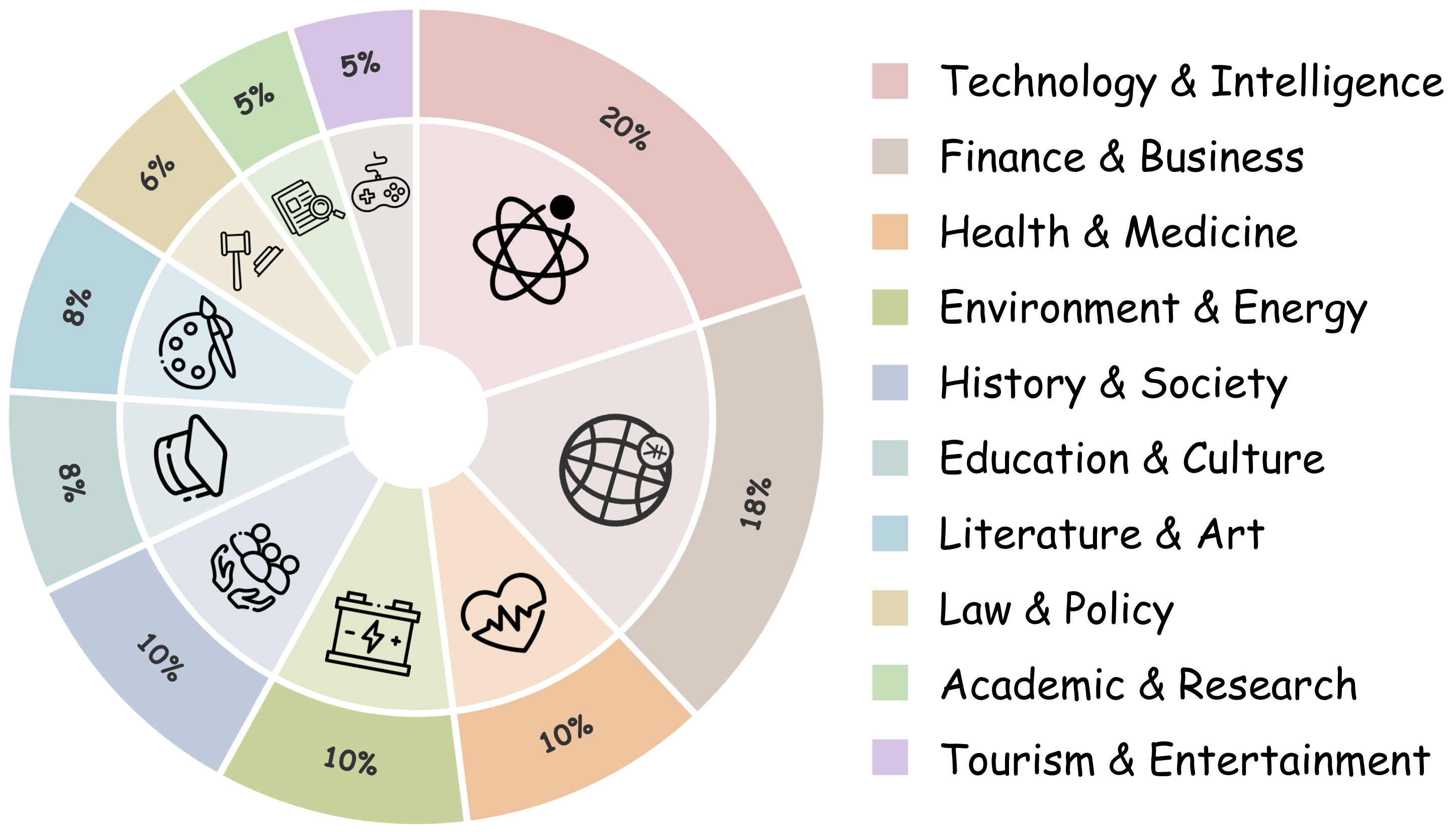
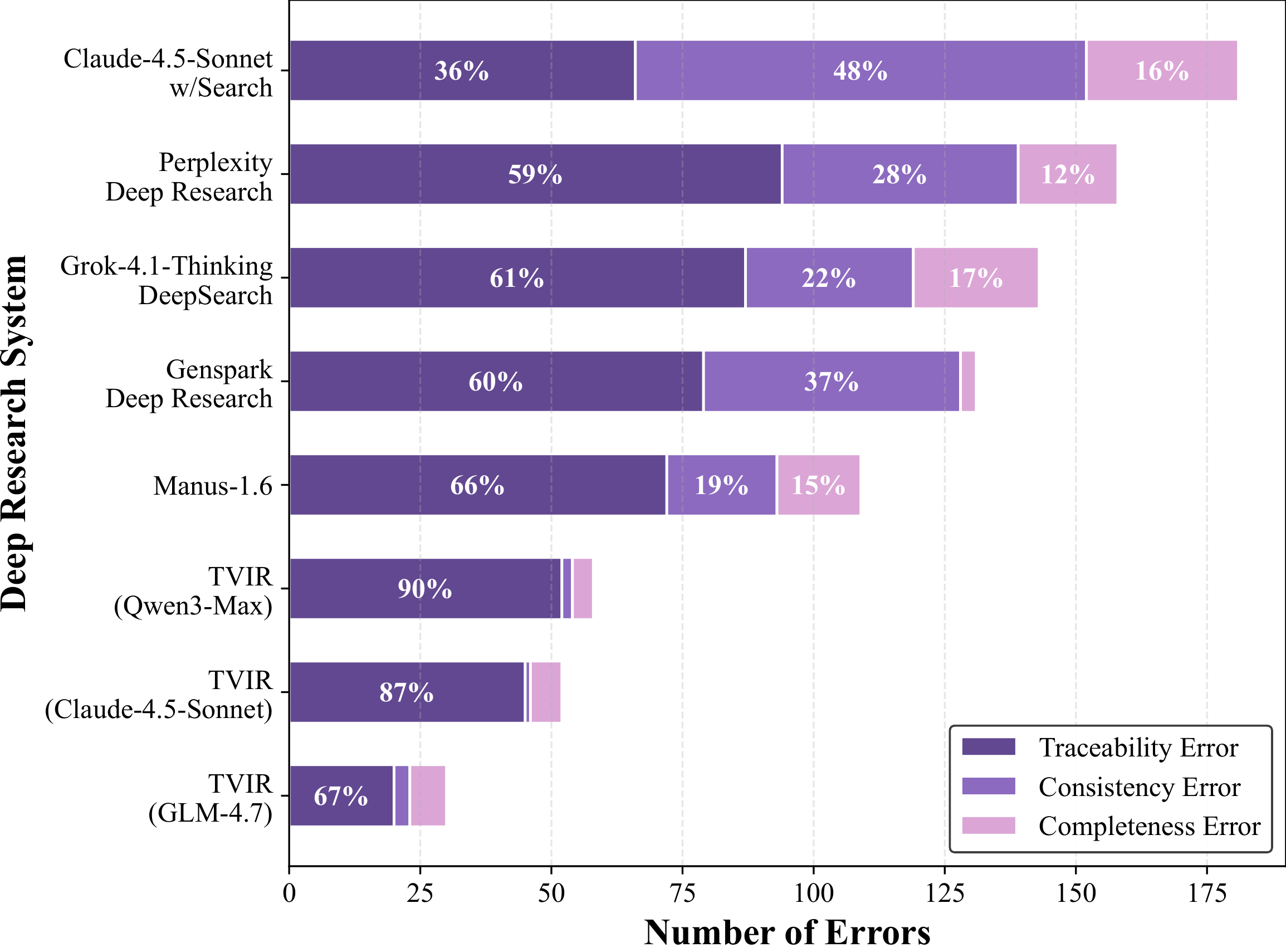
Figure 1: Comparison of representative deep research benchmarks. Existing benchmarks mainly focus on text-only or weakly multimodal reports, whereas TVIR-Bench requires text-visual interleaved reports with semantically grounded charts and retrieved images.