#1
Closed-source
Wan2.7
56.89
UAS
- IFS
- 82.02
- VQR
- 4.407
- SEM
- 87.90
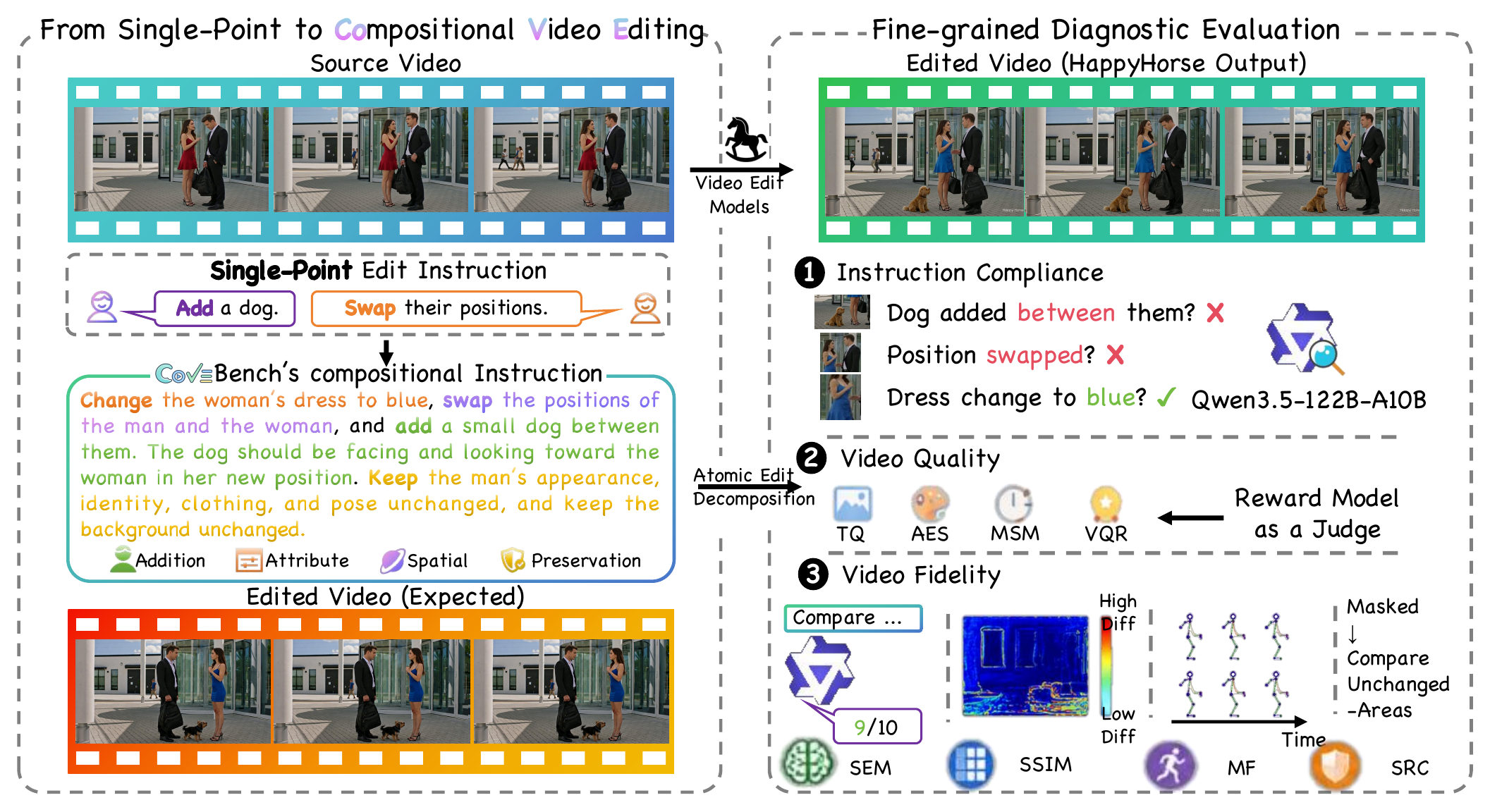
Compositional video editing evaluation
A diagnostic benchmark for real-world, multi-point video editing prompts, with fine-grained checklist evaluation across instruction compliance, video quality, and source fidelity.
Project demo
A short walkthrough of the benchmark interface, evaluation flow, and representative video editing examples.
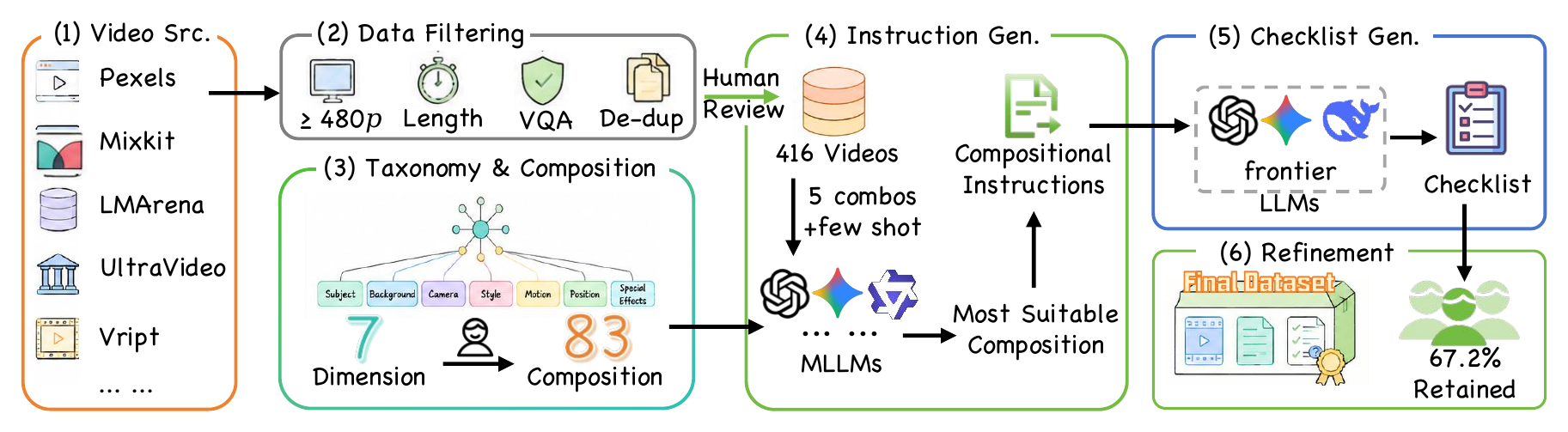
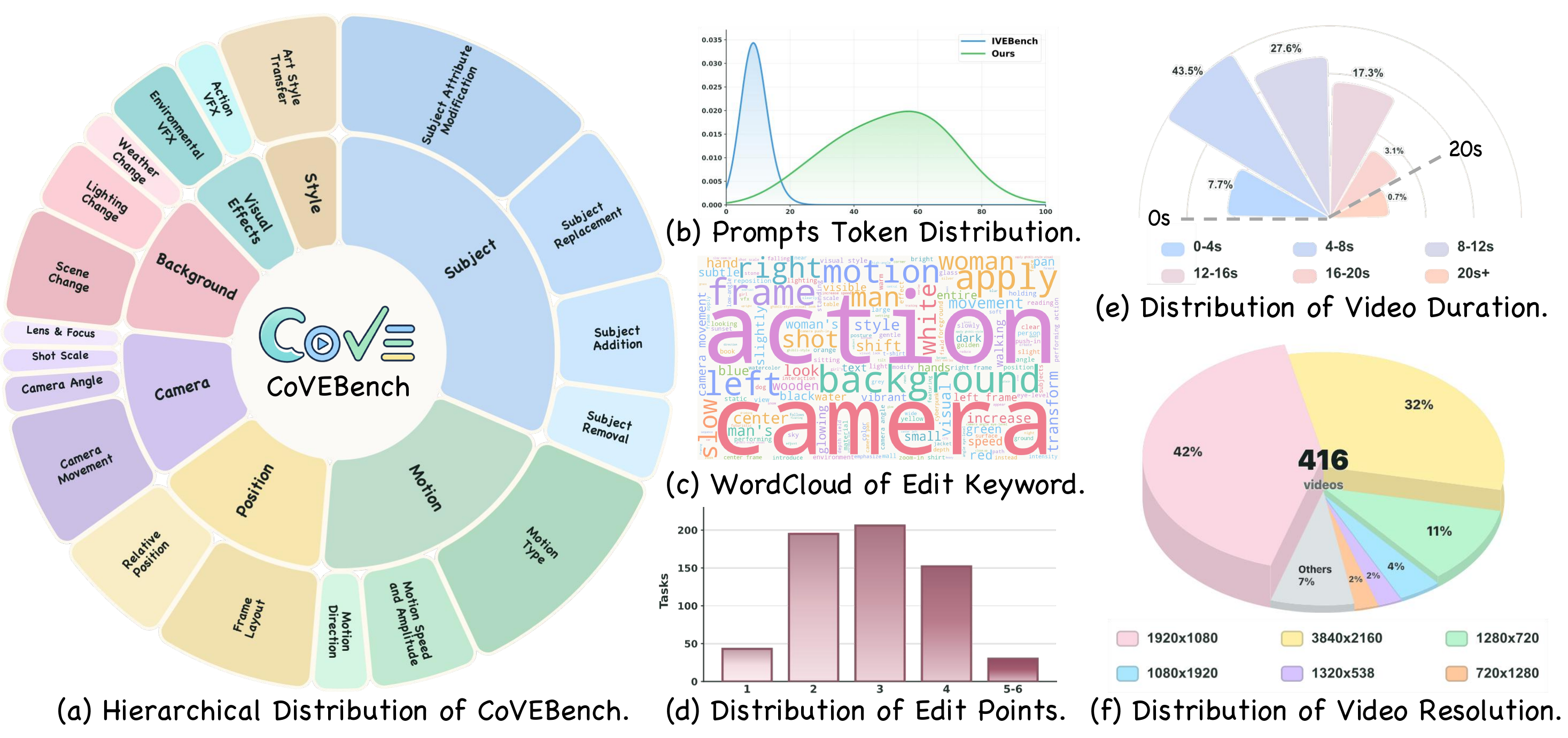
Benchmark construction
The benchmark emphasizes realistic compositional instructions instead of isolated, single-edit prompts. Videos are filtered for visual quality, editability, duration, resolution, and duplicate removal before being paired with diverse instructions and verifiable checklist questions.
Evaluation protocol
CoVEBench separates whether an edit was executed, whether the output remains visually plausible, and whether unrelated source content is preserved, enabling failures to be localized beyond a single aggregate score.
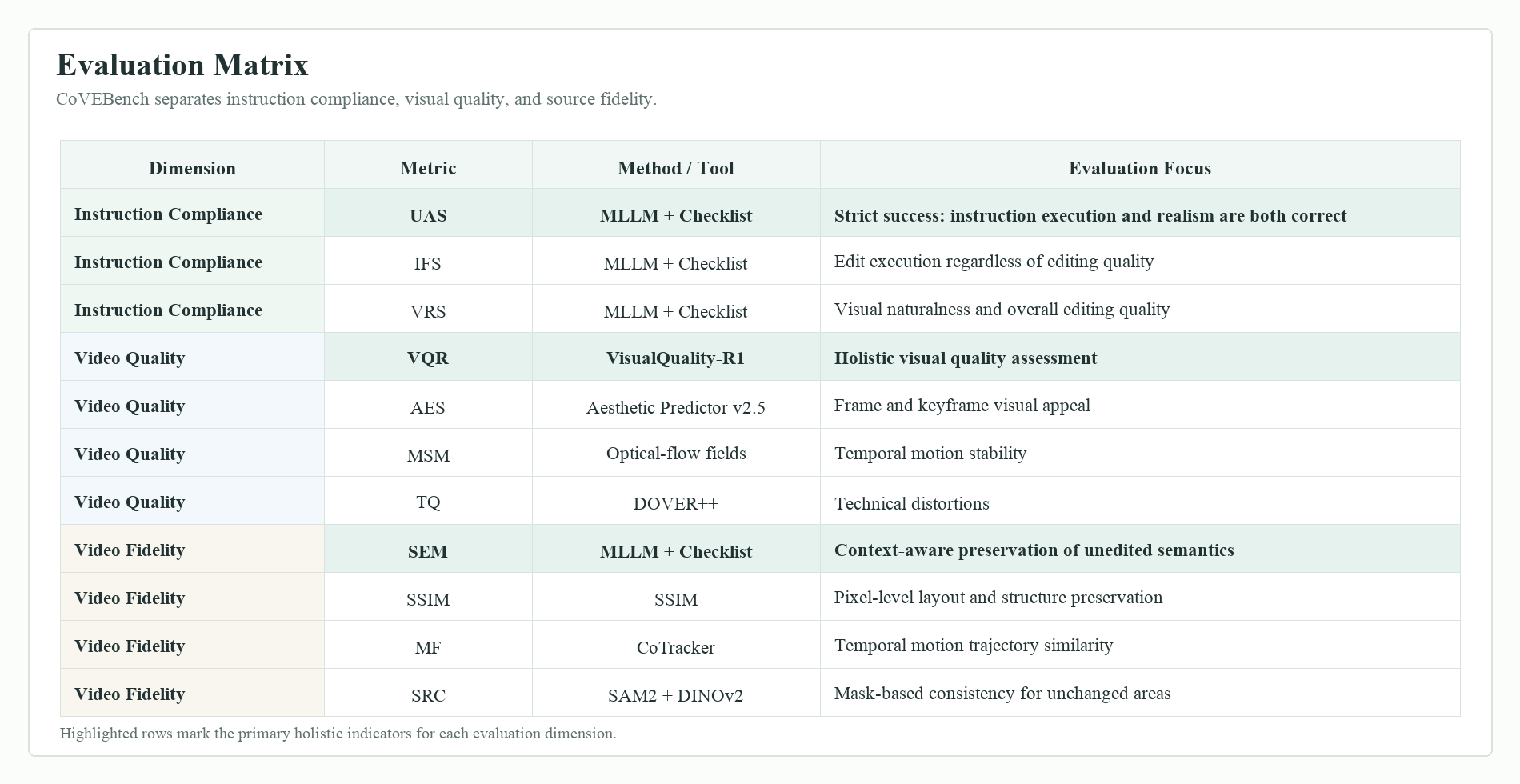
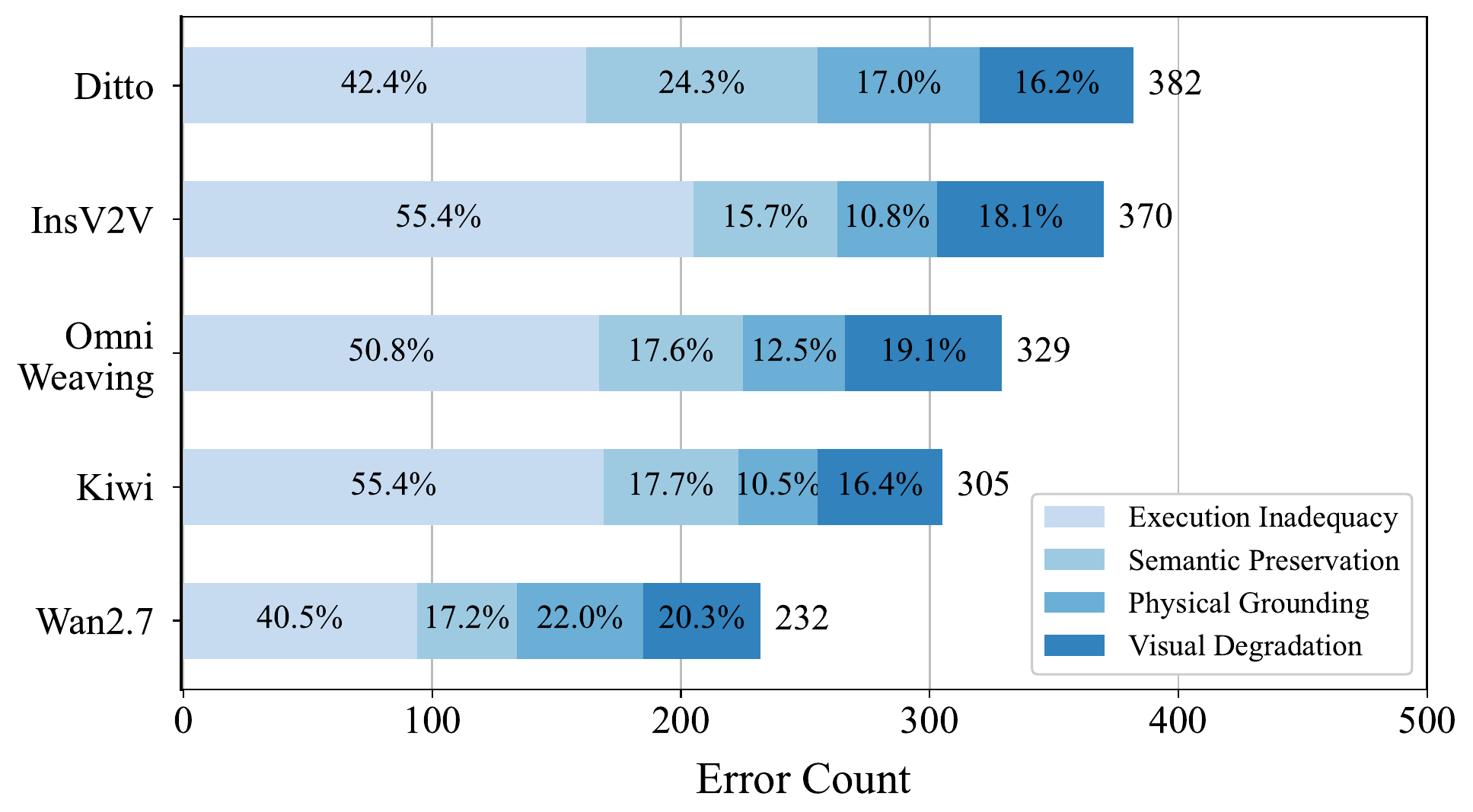
Main results
Strong proprietary systems lead the benchmark, but absolute union accuracy remains far below individual instruction-following and realism scores. This gap indicates that models can partially execute requested changes while still failing the full compositional requirement.
Leaderboard
Closed-source
Closed-source
Open-source
| Rank | Model | Source | UAS | IFS | VRS | VQR | AES | MSM | TQ | SEM | SSIM | MF | SRC |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| #1 | Wan2.7 | Closed | 56.89 | 82.02 | 79.97 | 4.407 | 5.077 | 0.692 | 18.223 | 87.90 | 0.482 | 0.896 | 0.815 |
| #2 | HappyHorse1.0 | Closed | 55.18 | 76.54 | 84.52 | 4.388 | 5.070 | 0.710 | 18.414 | 92.73 | 0.506 | 0.886 | 0.823 |
| #3 | OmniWeaving | Open | 30.14 | 57.18 | 61.75 | 3.660 | 4.135 | 0.709 | 15.092 | 85.05 | 0.463 | 0.891 | 0.781 |
| #4 | Kiwi | Open | 29.03 | 53.90 | 56.13 | 3.670 | 4.609 | 0.642 | 15.649 | 79.51 | 0.605 | 0.893 | 0.814 |
| #5 | Ditto | Open | 26.50 | 49.45 | 60.69 | 3.921 | 4.297 | 0.639 | 15.583 | 58.02 | 0.355 | 0.907 | 0.763 |
| #6 | Lucy | Open | 26.01 | 50.85 | 58.68 | 3.688 | 4.136 | 0.661 | 15.045 | 86.13 | 0.762 | 0.918 | 0.834 |
| #7 | ICVE | Open | 25.83 | 53.14 | 54.00 | 3.277 | 3.695 | 0.642 | 12.168 | 71.02 | 0.288 | 0.814 | 0.642 |
| #8 | ReCo | Open | 24.35 | 54.16 | 47.42 | 3.146 | 3.906 | 0.625 | 12.101 | 70.03 | 0.528 | 0.870 | 0.730 |
| #9 | InsV2V | Open | 14.61 | 37.18 | 47.36 | 3.307 | 4.327 | 0.698 | 10.501 | 77.85 | 0.280 | 0.886 | 0.740 |
| #10 | VACE | Open | 9.69 | 22.92 | 41.35 | 3.718 | 5.037 | 0.688 | 13.637 | 81.73 | 0.709 | 0.958 | 0.783 |
Wan2.7 and HappyHorse1.0 reach the best UAS scores, yet even the strongest model remains under 57% union accuracy on compositional edits.
Some systems improve instruction following by making stronger edits, but this can reduce semantic preservation and alter regions that should remain unchanged.
Joint editing achieves 30.63% UAS versus 23.70% for sequential editing, avoiding error accumulation and overwriting from intermediate generations.
Further analysis
Additional experiments show that longer temporal spans, more edit points, and longer instructions amplify the difficulty. Metric-human agreement remains high, supporting the evaluation protocol.
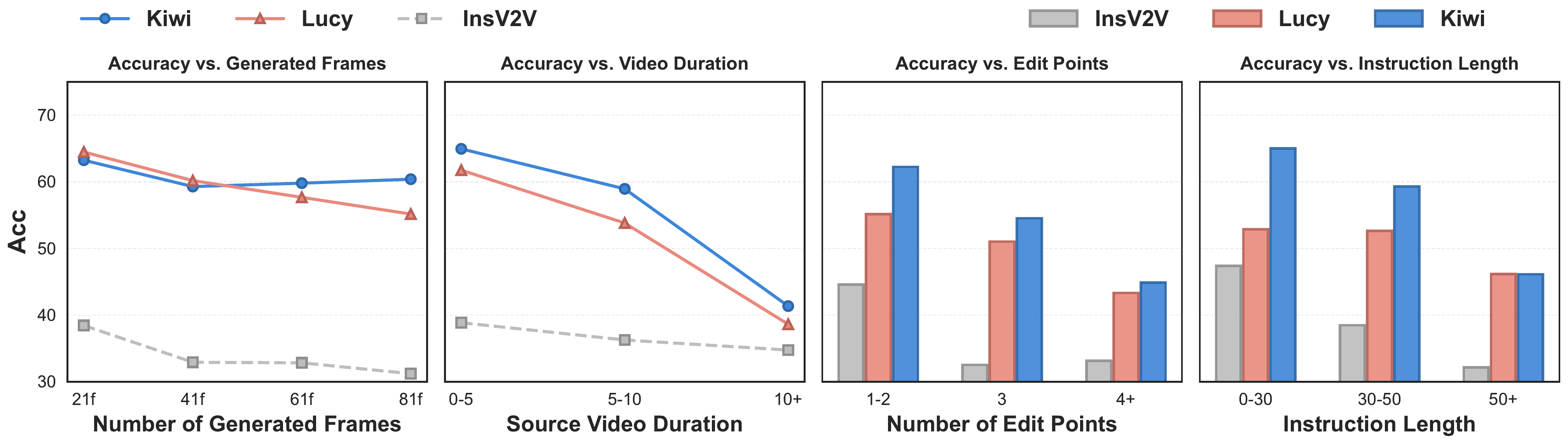
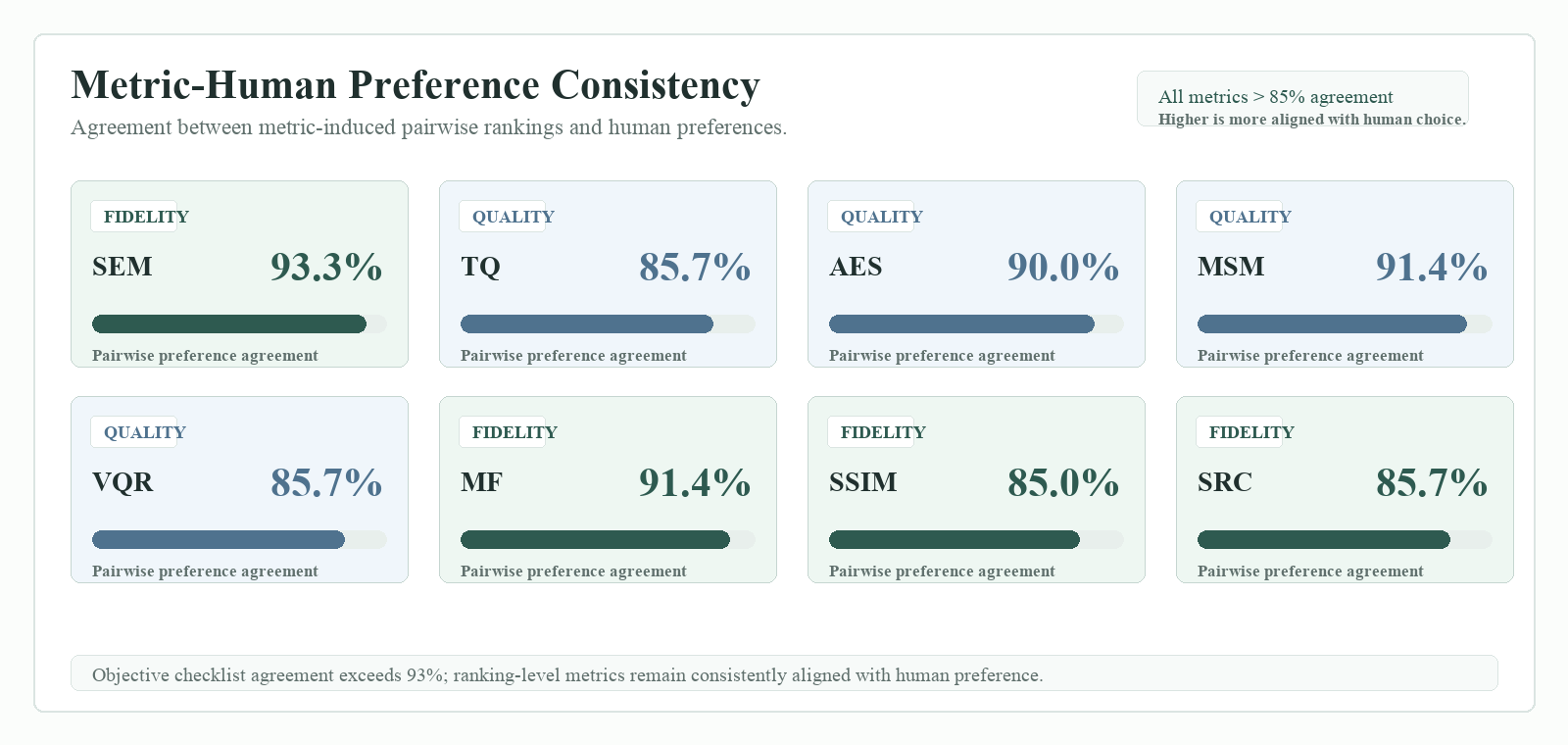
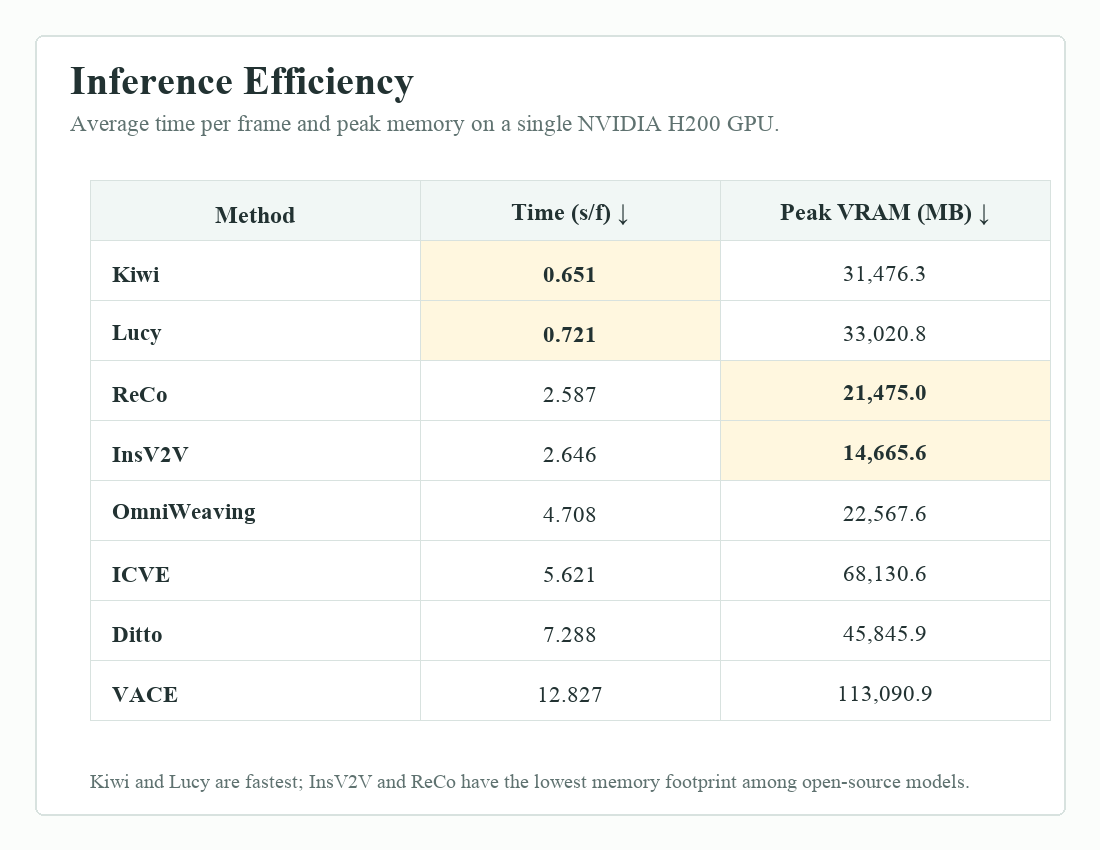
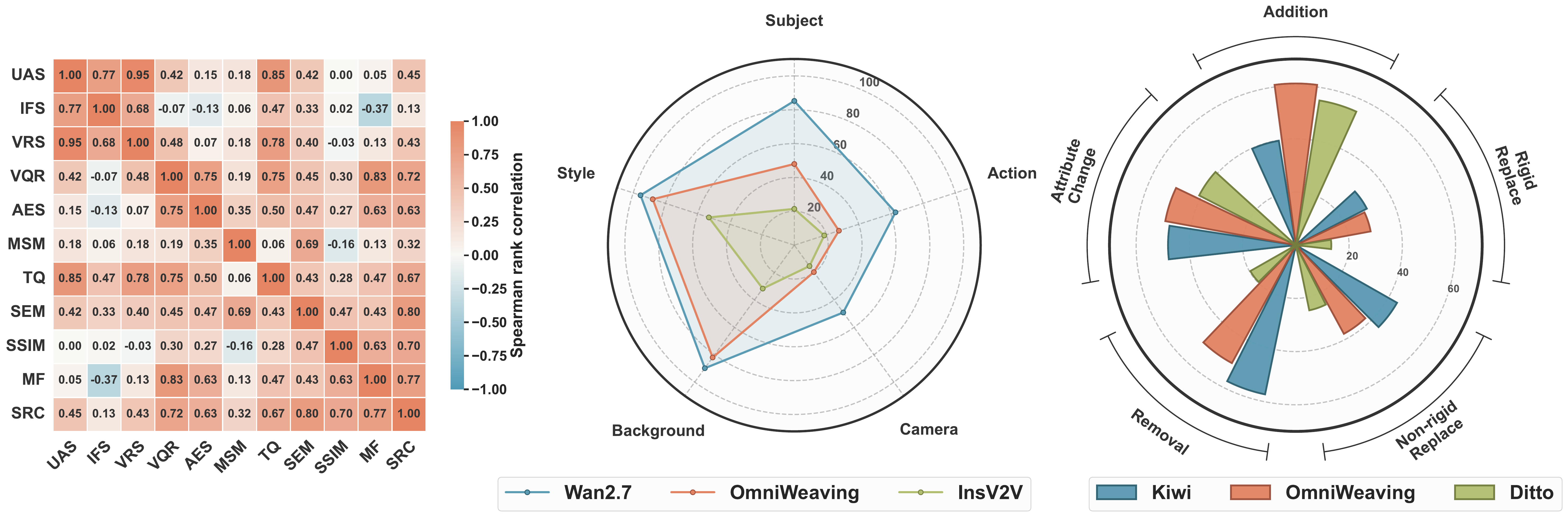
Diagnostic views
Aggregate scores hide important differences between editing categories. Camera control, motion edits, and subject operations remain particularly challenging, while style and background changes are more tractable for current models.
Examples
CoVEBench pairs visual samples with detailed checklist supervision, enabling model outputs to be inspected beyond a single global score.
Citation
If you find this benchmark useful for your research, please cite the project.
@misc{wu2026covebenchvideoeditingmodels,
title={CoVEBench: Can Video Editing Models Handle Complex Instructions?},
author={Jiangtao Wu and Jiaming Wang and Yiwen He and Yuanxing Zhang and Shihao Li and Dunyuan Liu and Xuedong Zhao and Jialu Chen and Zekun Moore Wang and Jiaheng Liu},
year={2026},
eprint={2606.08415},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2606.08415},
}